执行器¶
深度学习算法的训练、验证和测试通常都拥有相似的流程,因此, MMEngine 抽象出了执行器来负责通用的算法模型的训练、测试、推理任务。用户一般可以直接使用 MMEngine 中的默认执行器,也可以对执行器进行修改以满足定制化需求。
在介绍执行器的设计之前,我们先举几个例子来帮助用户理解为什么需要执行器。下面是一段使用 PyTorch 进行模型训练的伪代码:
model = ResNet()
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
train_dataset = ImageNetDataset(...)
train_dataloader = DataLoader(train_dataset, ...)
for i in range(max_epochs):
for data_batch in train_dataloader:
optimizer.zero_grad()
outputs = model(data_batch)
loss = loss_func(outputs, data_batch)
loss.backward()
optimizer.step()
下面是一段使用 PyTorch 进行模型测试的伪代码:
model = ResNet()
model.load_state_dict(torch.load(CKPT_PATH))
model.eval()
test_dataset = ImageNetDataset(...)
test_dataloader = DataLoader(test_dataset, ...)
for data_batch in test_dataloader:
outputs = model(data_batch)
acc = calculate_acc(outputs, data_batch)
下面是一段使用 PyTorch 进行模型推理的伪代码:
model = ResNet()
model.load_state_dict(torch.load(CKPT_PATH))
model.eval()
for img in imgs:
prediction = model(img)
可以从上面的三段代码看出,这三个任务的执行流程都可以归纳为构建模型、读取数据、循环迭代等步骤。上述代码都是以图像分类为例,但不论是图像分类还是目标检测或是图像分割,都脱离不了这套范式。 因此,我们将模型的训练、验证、测试的流程整合起来,形成了执行器。在执行器中,我们只需要准备好模型、数据等任务必须的模块或是这些模块的配置文件,执行器会自动完成任务流程的准备和执行。 通过使用执行器以及 MMEngine 中丰富的功能模块,用户不再需要手动搭建训练测试的流程,也不再需要去处理分布式与非分布式训练的区别,可以专注于算法和模型本身。
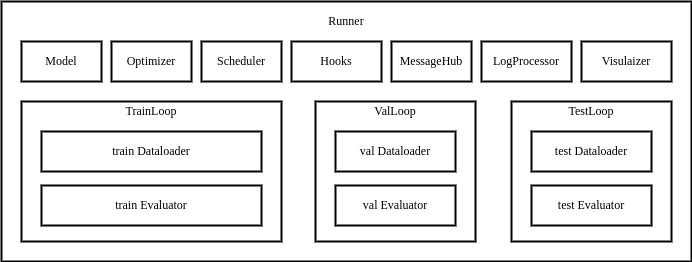
MMEngine 的执行器内包含训练、测试、验证所需的各个模块,以及循环控制器(Loop)和钩子(Hook)。用户通过提供配置文件或已构建完成的模块,执行器将自动完成运行环境的配置,模块的构建和组合,最终通过循环控制器执行任务循环。执行器对外提供三个接口:train, val, test,当调用这三个接口时,便会运行对应的循环控制器,并在循环的运行过程中调用钩子模块各个位点的钩子函数。
当用户构建一个执行器并调用训练、验证、测试的接口时,执行器的执行流程如下:创建工作目录 -> 配置运行环境 -> 准备任务所需模块 -> 注册钩子 -> 运行循环
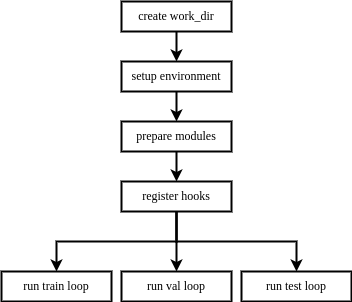
执行器具有延迟初始化(Lazy Initialization)的特性,在初始化执行器时,并不需要依赖训练、验证和测试的全量模块,只有当运行某个循环控制器时,才会检查所需模块是否构建。因此,若用户只需要执行训练、验证或测试中的某一项功能,只需提供对应的模块或模块的配置即可。
循环控制器¶
在 MMEngine 中,我们将任务的执行流程抽象成循环控制器(Loop),因为大部分的深度学习任务执行流程都可以归纳为模型在一组或多组数据上进行循环迭代。 MMEngine 内提供了四种默认的循环控制器:
EpochBasedTrainLoop 基于轮次的训练循环
IterBasedTrainLoop 基于迭代次数的训练循环
ValLoop 标准的验证循环
TestLoop 标准的测试循环
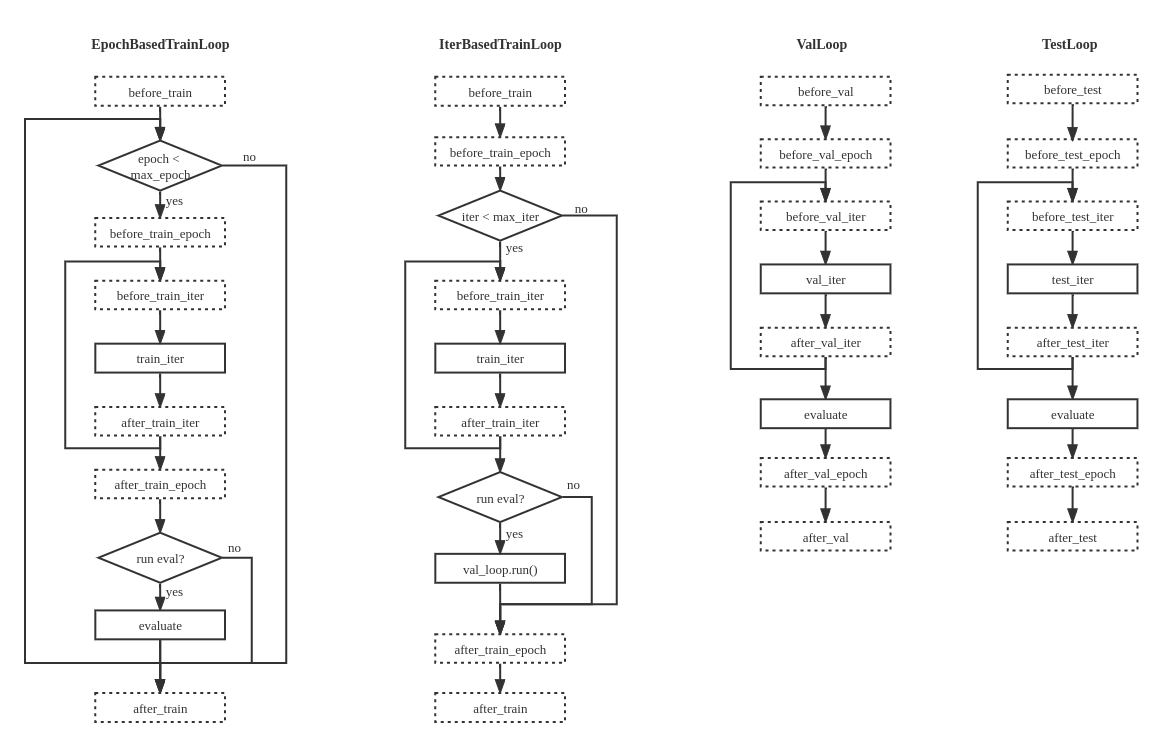
MMEngine 中的默认执行器和循环控制器能够完成大部分的深度学习任务,但不可避免会存在无法满足的情况。有的用户希望能够对执行器进行更多自定义修改,因此,MMEngine 支持自定义模型的训练、验证以及测试的流程。
用户可以通过继承循环基类来实现自己的训练流程。循环基类需要提供两个输入:runner 执行器的实例和 dataloader 循环所需要迭代的迭代器。
用户如果有自定义的需求,也可以增加更多的输入参数。MMEngine 中同样提供了 LOOPS 注册器对循环类进行管理,用户可以向注册器内注册自定义的循环模块,然后在配置文件的 train_cfg、val_cfg、test_cfg 中增加 type 字段来指定使用何种循环。
用户可以在自定义的循环中实现任意的执行逻辑,也可以增加或删减钩子(hook)点位,但需要注意的是一旦钩子点位被修改,默认的钩子函数可能不会被执行,导致一些训练过程中默认发生的行为发生变化。
因此,我们强烈建议用户按照本文档中定义的循环执行流程图以及钩子设计 去重载循环基类。
from mmengine.registry import LOOPS, HOOKS
from mmengine.runner import BaseLoop
from mmengine.hooks import Hook
# 自定义验证循环
@LOOPS.register_module()
class CustomValLoop(BaseLoop):
def __init__(self, runner, dataloader, evaluator, dataloader2):
super().__init__(runner, dataloader, evaluator)
self.dataloader2 = runner.build_dataloader(dataloader2)
def run(self):
self.runner.call_hooks('before_val_epoch')
for idx, data_batch in enumerate(self.dataloader):
self.runner.call_hooks(
'before_val_iter', batch_idx=idx, data_batch=data_batch)
outputs = self.run_iter(idx, data_batch)
self.runner.call_hooks(
'after_val_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
metric = self.evaluator.evaluate()
# 增加额外的验证循环
for idx, data_batch in enumerate(self.dataloader2):
# 增加额外的钩子点位
self.runner.call_hooks(
'before_valloader2_iter', batch_idx=idx, data_batch=data_batch)
self.run_iter(idx, data_batch)
# 增加额外的钩子点位
self.runner.call_hooks(
'after_valloader2_iter', batch_idx=idx, data_batch=data_batch, outputs=outputs)
metric2 = self.evaluator.evaluate()
...
self.runner.call_hooks('after_val_epoch')
# 定义额外点位的钩子类
@HOOKS.register_module()
class CustomValHook(Hook):
def before_valloader2_iter(self, batch_idx, data_batch):
...
def after_valloader2_iter(self, batch_idx, data_batch, outputs):
...
上面的例子中实现了一个与默认验证循环不一样的自定义验证循环,它在两个不同的验证集上进行验证,同时对第二次验证增加了额外的钩子点位,并在最后对两个验证结果进行进一步的处理。在实现了自定义的循环类之后,只需要在配置文件的 val_cfg 内设置 type='CustomValLoop',并添加额外的配置即可。
# 自定义验证循环
val_cfg = dict(type='CustomValLoop', dataloader2=dict(dataset=dict(type='ValDataset2'), ...))
# 额外点位的钩子
custom_hooks = [dict(type='CustomValHook')]
自定义执行器¶
更进一步,如果默认执行器中依然有其他无法满足需求的部分,用户可以像自定义其他模块一样,通过继承重写的方式,实现自定义的执行器。执行器同样也可以通过注册器进行管理。具体实现流程与其他模块无异:继承 MMEngine 中的 Runner,重写需要修改的函数,添加进 RUNNERS 注册器中,最后在配置文件中指定 runner_type 即可。
from mmengine.registry import RUNNERS
from mmengine.runner import Runner
@RUNNERS.register_module()
class CustomRunner(Runner):
def setup_env(self):
...
上述例子实现了一个自定义的执行器,并重写了 setup_env 函数,然后添加进了 RUNNERS 注册器中,完成了这些步骤之后,便可以在配置文件中设置 runner_type='CustomRunner' 来构建自定义的执行器。
你可能还想阅读执行器的教程或者执行器的 API 文档。