模型精度评测¶
评测指标与评测器¶
在模型验证和模型测试中,通常需要对模型精度做定量评测。在 MMEngine 中实现了评测指标(Metric)和评测器(Evaluator)来完成这一功能。
评测指标 用于根据测试数据和模型预测结果,完成特定模型精度指标的计算。在 OpenMMLab 各算法库中提供了对应任务的常用评测指标,如 MMPretrain 中提供了Accuracy 用于计算分类模型的 Top-k 分类正确率;MMDetection 中提供了 COCOMetric 用于计算目标检测模型的 AP,AR 等评测指标。评测指标与数据集解耦,如 COCOMetric 也可用于 COCO 以外的目标检测数据集上。
评测器 是评测指标的上层模块,通常包含一个或多个评测指标。评测器的作用是在模型评测时完成必要的数据格式转换,并调用评测指标计算模型精度。评测器通常由执行器或测试脚本构建,分别用于在线评测和离线评测。
评测指标基类 BaseMetric¶
评测指标基类 BaseMetric 是一个抽象类,初始化参数如下:
collect_device:在分布式评测中用于同步结果的设备名,如'cpu'或'gpu'。prefix:评测指标名前缀,用以区别多个同名的评测指标。如果该参数未给定,则会尝试使用类属性default_prefix作为前缀。
class BaseMetric(metaclass=ABCMeta):
default_prefix: Optional[str] = None
def __init__(self,
collect_device: str = 'cpu',
prefix: Optional[str] = None) -> None:
...
BaseMetric 有以下 2 个重要的方法需要在子类中重写:
process()用于处理每个批次的测试数据和模型预测结果。处理结果应存放在self.results列表中,用于在处理完所有测试数据后计算评测指标。该方法具有以下 2 个参数:data_batch:一个批次的测试数据样本,通常直接来自与数据加载器data_samples:对应的模型预测结果 该方法没有返回值。函数接口定义如下:
@abstractmethod def process(self, data_batch: Any, data_samples: Sequence[dict]) -> None: """Process one batch of data samples and predictions. The processed results should be stored in ``self.results``, which will be used to compute the metrics when all batches have been processed. Args: data_batch (Any): A batch of data from the dataloader. data_samples (Sequence[dict]): A batch of outputs from the model. """
compute_metrics()用于计算评测指标,并将所评测指标存放在一个字典中返回。该方法有以下 1 个参数:results:列表类型,存放了所有批次测试数据经过process()方法处理后得到的结果 该方法返回一个字典,里面保存了评测指标的名称和对应的评测值。函数接口定义如下:
@abstractmethod def compute_metrics(self, results: list) -> dict: """Compute the metrics from processed results. Args: results (list): The processed results of each batch. Returns: dict: The computed metrics. The keys are the names of the metrics, and the values are corresponding results. """
其中,compute_metrics() 会在 evaluate() 方法中被调用;后者在计算评测指标前,会在分布式测试时收集和汇总不同 rank 的中间处理结果。
需要注意的是,self.results 中存放的具体类型取决于评测指标子类的实现。例如,当测试样本或模型输出数据量较大(如语义分割、图像生成等任务),不宜全部存放在内存中时,可以在 self.results 中存放每个批次计算得到的指标,并在 compute_metrics() 中汇总;或将每个批次的中间结果存储到临时文件中,并在 self.results 中存放临时文件路径,最后由 compute_metrics() 从文件中读取数据并计算指标。
模型精度评测流程¶
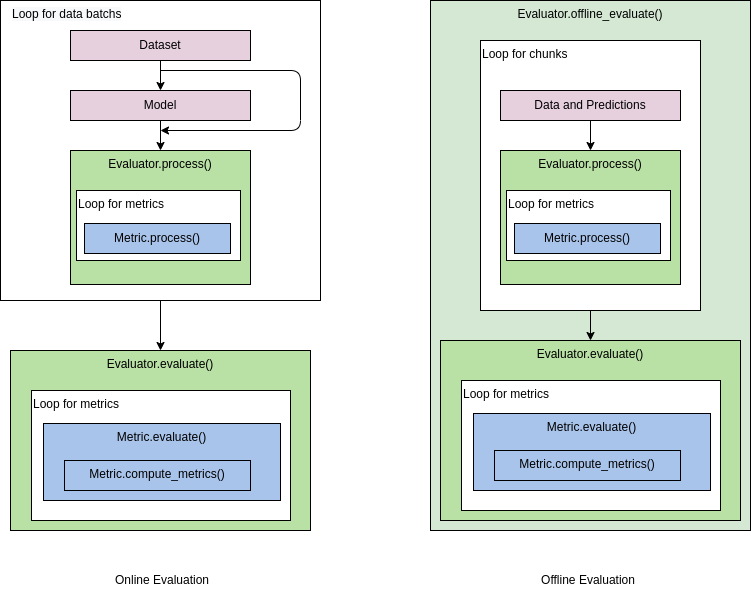
通常,模型精度评测的过程如下图所示。
在线评测:测试数据通常会被划分为若干批次(batch)。通过一个循环,依次将每个批次的数据送入模型,得到对应的预测结果,并将测试数据和模型预测结果送入评测器。评测器会调用评测指标的 process() 方法对数据和预测结果进行处理。当循环结束后,评测器会调用评测指标的 evaluate() 方法,可计算得到对应指标的模型精度。
离线评测:与在线评测过程类似,区别是直接读取预先保存的模型预测结果来进行评测。评测器提供了 offline_evaluate 接口,用于在离线方式下调用评测指标来计算模型精度。为了避免同时处理大量数据导致内存溢出,离线评测时会将测试数据和预测结果分成若干个块(chunk)进行处理,类似在线评测中的批次。
增加自定义评测指标¶
在 OpenMMLab 的各个算法库中,已经实现了对应方向的常用评测指标。如 MMDetection 中提供了 COCO 评测指标,MMPretrain 中提供了 Accuracy、F1Score 等评测指标等。
用户也可以增加自定义的评测指标。具体方法可以参考教程文档中给出的示例。