优化器参数调整策略(Parameter Scheduler)¶
在模型训练过程中,我们往往不是采用固定的优化参数,例如学习率等,会随着训练轮数的增加进行调整。最简单常见的学习率调整策略就是阶梯式下降,例如每隔一段时间将学习率降低为原来的几分之一。PyTorch 中有学习率调度器 LRScheduler 来对各种不同的学习率调整方式进行抽象,但支持仍然比较有限,在 MMEngine 中,我们对其进行了拓展,实现了更通用的参数调度器,可以对学习率、动量等优化器相关的参数进行调整,并且支持多个调度器进行组合,应用更复杂的调度策略。
参数调度器的使用¶
我们先简单介绍一下如何使用 PyTorch 内置的学习率调度器来进行学习率的调整:
如何使用 PyTorch 内置的学习率调度器调整学习率
下面是参考 PyTorch 官方文档 实现的一个例子,我们构造一个 ExponentialLR,并且在每个 epoch 结束后调用 scheduler.step(),实现了随 epoch 指数下降的学习率调整策略。
import torch
from torch.optim import SGD
from torch.optim.lr_scheduler import ExponentialLR
model = torch.nn.Linear(1, 1)
dataset = [torch.randn((1, 1, 1)) for _ in range(20)]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(10):
for data in dataset:
optimizer.zero_grad()
output = model(data)
loss = 1 - output
loss.backward()
optimizer.step()
scheduler.step()
在 mmengine.optim.scheduler 中,我们支持大部分 PyTorch 中的学习率调度器,例如 ExponentialLR,LinearLR,StepLR,MultiStepLR 等,使用方式也基本一致,所有支持的调度器见调度器接口文档。同时增加了对动量的调整,在类名中将 LR 替换成 Momentum 即可,例如 ExponentialMomentum,LinearMomentum。更进一步地,我们实现了通用的参数调度器 ParamScheduler,用于调整优化器的中的其他参数,包括 weight_decay 等。这个特性可以很方便地配置一些新算法中复杂的调整策略。
和 PyTorch 文档中所给示例不同,MMEngine 中通常不需要手动来实现训练循环以及调用 optimizer.step(),而是在执行器(Runner)中对训练流程进行自动管理,同时通过 ParamSchedulerHook 来控制参数调度器的执行。
使用单一的学习率调度器¶
如果整个训练过程只需要使用一个学习率调度器, 那么和 PyTorch 自带的学习率调度器没有差异。
# 基于手动构建学习率调度器的例子
from torch.optim import SGD
from mmengine.runner import Runner
from mmengine.optim.scheduler import MultiStepLR
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.9)
param_scheduler = MultiStepLR(optimizer, milestones=[8, 11], gamma=0.1)
runner = Runner(
model=model,
optim_wrapper=dict(
optimizer=optimizer),
param_scheduler=param_scheduler,
...
)
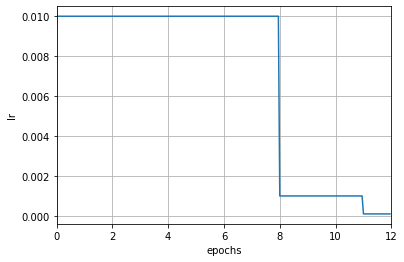
如果配合注册器和配置文件使用的话,我们可以设置配置文件中的 param_scheduler 字段来指定调度器, 执行器(Runner)会根据此字段以及执行器中的优化器自动构建学习率调度器:
# 在配置文件中设置学习率调度器字段
param_scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.1)
注意这里增加了初始化参数 by_epoch,控制的是学习率调整频率,当其为 True 时表示按轮次(epoch)调整,为 False 时表示按迭代次数(iteration)调整,默认值为 True。在上面的例子中,表示按照轮次进行调整,此时其他参数的单位均为 epoch,例如 milestones 中的 [8, 11] 表示第 8 和 11 轮次结束时,学习率将会被调整为上一轮次的 0.1 倍。
当修改了学习率调整频率后,调度器中与计数相关设置的含义也会相应被改变。当 by_epoch=True 时,milestones 中的数字表示在哪些轮次进行学习率衰减,而当 by_epoch=False 时则表示在进行到第几次迭代时进行学习率衰减。下面是一个按照迭代次数进行调整的例子,在第 600 和 800 次迭代结束时,学习率将会被调整为原来的 0.1 倍。
param_scheduler = dict(type='MultiStepLR', by_epoch=False, milestones=[600, 800], gamma=0.1)
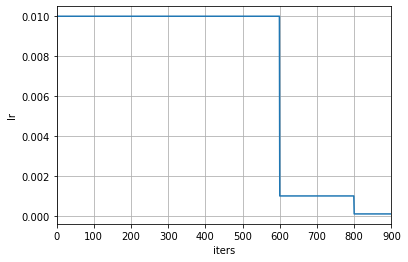
若用户希望在配置调度器时按轮次填写参数的同时使用基于迭代的更新频率,MMEngine 的调度器也提供了自动换算的方式。用户可以调用 build_iter_from_epoch 方法,并提供每个训练轮次的迭代次数,即可构造按迭代次数更新的调度器对象:
epoch_length = len(train_dataloader)
param_scheduler = MultiStepLR.build_iter_from_epoch(optimizer, milestones=[8, 11], gamma=0.1, epoch_length=epoch_length)
如果使用配置文件构建调度器,只需要在配置中加入 convert_to_iter_based=True,执行器会自动调用 build_iter_from_epoch 将基于轮次的配置文件转换为基于迭代次数的调度器对象:
param_scheduler = dict(type='MultiStepLR', by_epoch=True, milestones=[8, 11], gamma=0.1, convert_to_iter_based=True)
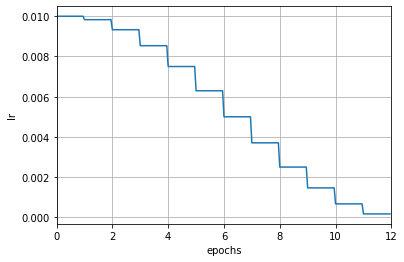
为了能直观感受这两种模式的区别,我们这里再举一个例子。下面是一个按轮次更新的余弦退火(CosineAnnealing)学习率调度器,学习率仅在每个轮次结束后被修改:
param_scheduler = dict(type='CosineAnnealingLR', by_epoch=True, T_max=12)
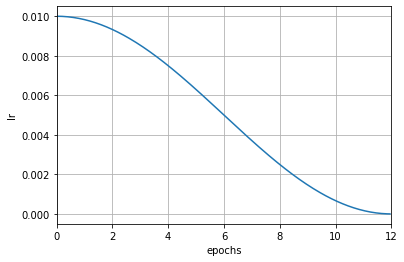
而在使用自动换算后,学习率会在每次迭代后被修改。从下图可以看出,学习率的变化更为平滑。
param_scheduler = dict(type='CosineAnnealingLR', by_epoch=True, T_max=12, convert_to_iter_based=True)
组合多个学习率调度器(以学习率预热为例)¶
有些算法在训练过程中,并不是自始至终按照某个调度策略进行学习率调整的。最常见的例子是学习率预热,比如在训练刚开始的若干迭代次数使用线性的调整策略将学习率从一个较小的值增长到正常,然后按照另外的调整策略进行正常训练。
MMEngine 支持组合多个调度器一起使用,只需将配置文件中的 scheduler 字段修改为一组调度器配置的列表,SchedulerStepHook 可以自动对调度器列表进行处理。下面的例子便实现了学习率预热。
param_scheduler = [
# 线性学习率预热调度器
dict(type='LinearLR',
start_factor=0.001,
by_epoch=False, # 按迭代更新学习率
begin=0,
end=50), # 预热前 50 次迭代
# 主学习率调度器
dict(type='MultiStepLR',
by_epoch=True, # 按轮次更新学习率
milestones=[8, 11],
gamma=0.1)
]
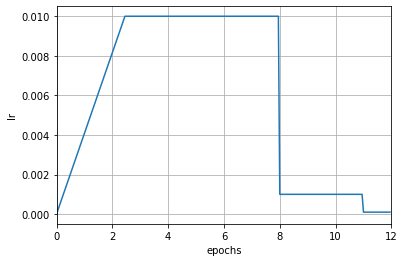
注意这里增加了 begin 和 end 参数,这两个参数指定了调度器的生效区间。生效区间通常只在多个调度器组合时才需要去设置,使用单个调度器时可以忽略。当指定了 begin 和 end 参数时,表示该调度器只在 [begin, end) 区间内生效,其单位是由 by_epoch 参数决定。上述例子中预热阶段 LinearLR 的 by_epoch 为 False,表示该调度器只在前 50 次迭代生效,超过 50 次迭代后此调度器不再生效,由第二个调度器来控制学习率,即 MultiStepLR。在组合不同调度器时,各调度器的 by_epoch 参数不必相同。
这里再举一个例子:
param_scheduler = [
# 在 [0, 100) 迭代时使用线性学习率
dict(type='LinearLR',
start_factor=0.001,
by_epoch=False,
begin=0,
end=100),
# 在 [100, 900) 迭代时使用余弦学习率
dict(type='CosineAnnealingLR',
T_max=800,
by_epoch=False,
begin=100,
end=900)
]
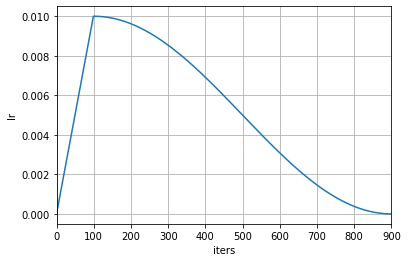
上述例子表示在训练的前 100 次迭代时使用线性的学习率预热,然后在第 100 到第 900 次迭代时使用周期为 800 的余弦退火学习率调度器使学习率按照余弦函数逐渐下降为 0 。
我们可以组合任意多个调度器,既可以使用 MMEngine 中已经支持的调度器,也可以实现自定义的调度器。
如果相邻两个调度器的生效区间没有紧邻,而是有一段区间没有被覆盖,那么这段区间的学习率维持不变。而如果两个调度器的生效区间发生了重叠,则对多组调度器叠加使用,学习率的调整会按照调度器配置文件中的顺序触发(行为与 PyTorch 中 ChainedScheduler 一致)。
在一般情况下,我们推荐用户在训练的不同阶段使用不同的学习率调度策略来避免调度器的生效区间发生重叠。如果确实需要将两个调度器叠加使用,则需要十分小心,避免学习率的调整与预期不符。
如何调整其他参数¶
动量¶
和学习率一样, 动量也是优化器参数组中一组可以调度的参数。 动量调度器(momentum scheduler)的使用方法和学习率调度器完全一样。同样也只需要将动量调度器的配置添加进配置文件中的 param_scheduler 字段的列表中即可。
示例:
param_scheduler = [
# the lr scheduler
dict(type='LinearLR', ...),
# 动量调度器
dict(type='LinearMomentum',
start_factor=0.001,
by_epoch=False,
begin=0,
end=1000)
]
通用的参数调度器¶
MMEngine 还提供了一组通用的参数调度器用于调度优化器的 param_groups 中的其他参数,将学习率调度器类名中的 LR 改为 Param 即可,例如 LinearParamScheduler。用户可以通过设置参数调度器的 param_name 变量来选择想要调度的参数。
下面是一个通过自定义参数名来调度的例子:
param_scheduler = [
dict(type='LinearParamScheduler',
param_name='lr', # 调度 `optimizer.param_groups` 中名为 'lr' 的变量
start_factor=0.001,
by_epoch=False,
begin=0,
end=1000)
]
这里设置的参数名是 lr,因此这个调度器的作用等同于直接使用学习率调度器 LinearLRScheduler。
除了动量之外,用户也可以对 optimizer.param_groups 中的其他参数名进行调度,可调度的参数取决于所使用的优化器。例如,当使用带 weight_decay 的 SGD 优化器时,可以按照以下示例对调整 weight_decay:
param_scheduler = [
dict(type='LinearParamScheduler',
param_name='weight_decay', # 调度 `optimizer.param_groups` 中名为 'weight_decay' 的变量
start_factor=0.001,
by_epoch=False,
begin=0,
end=1000)
]