数据变换 (Data Transform)¶
在 OpenMMLab 算法库中,数据集的构建和数据的准备是相互解耦的。通常,数据集的构建只对数据集进行解析,记录每个样本的基本信息;而数据的准备则是通过一系列的数据变换,根据样本的基本信息进行数据加载、预处理、格式化等操作。
使用数据变换类¶
在 MMEngine 中,我们使用各种可调用的数据变换类来进行数据的操作。这些数据变换类可以接受若干配置参数进行实例化,之后通过调用的方式对输入的数据字典进行处理。同时,我们约定所有数据变换都接受一个字典作为输入,并将处理后的数据输出为一个字典。一个简单的例子如下:
备注
MMEngine 中仅约定了数据变换类的规范,常用的数据变换类实现及基类都在 MMCV 中,因此在本篇教程需要提前安装好 MMCV,参见 MMCV 安装教程。
>>> import numpy as np
>>> from mmcv.transforms import Resize
>>>
>>> transform = Resize(scale=(224, 224))
>>> data_dict = {'img': np.random.rand(256, 256, 3)}
>>> data_dict = transform(data_dict)
>>> print(data_dict['img'].shape)
(224, 224, 3)
在配置文件中使用¶
在配置文件中,我们将一系列数据变换组合成为一个列表,称为数据流水线(Data Pipeline),传给数据集的 pipeline 参数。通常数据流水线由以下几个部分组成:
数据加载,通常使用
LoadImageFromFile标签加载,通常使用
LoadAnnotations数据处理及增强,例如
RandomResize数据格式化,根据任务不同,在各个仓库使用自己的变换操作,通常名为
PackXXXInputs,其中 XXX 是任务的名称,如分类任务中的PackClsInputs。
以分类任务为例,我们在下图展示了一个典型的数据流水线。对每个样本,数据集中保存的基本信息是一个如图中最左侧所示的字典,之后每经过一个由蓝色块代表的数据变换操作,数据字典中都会加入新的字段(标记为绿色)或更新现有的字段(标记为橙色)。
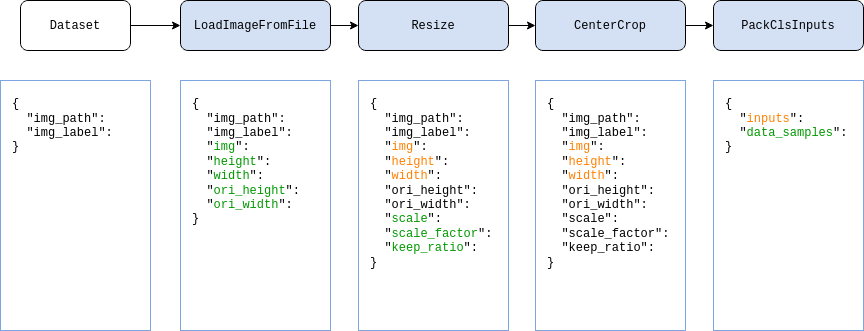
如果我们希望在测试中使用上述数据流水线,则配置文件如下所示:
test_dataloader = dict(
batch_size=32,
dataset=dict(
type='ImageNet',
data_root='data/imagenet',
pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=256, keep_ratio=True),
dict(type='CenterCrop', crop_size=224),
dict(type='PackClsInputs'),
]
)
)
常用的数据变换类¶
按照功能,常用的数据变换类可以大致分为数据加载、数据预处理与增强、数据格式化。我们在 MMCV 中提供了一系列常用的数据变换类:
数据加载¶
为了支持大规模数据集的加载,通常在数据集初始化时不加载数据,只加载相应的路径。因此需要在数据流水线中进行具体数据的加载。
数据变换类 |
功能 |
|---|---|
根据路径加载图像 |
|
加载和组织标注信息,如 bbox、语义分割图等 |
数据预处理及增强¶
数据预处理和增强通常是对图像本身进行变换,如裁剪、填充、缩放等。
数据变换类 |
功能 |
|---|---|
填充图像边缘 |
|
居中裁剪 |
|
对图像进行归一化 |
|
按照指定尺寸或比例缩放图像 |
|
缩放图像至指定范围的随机尺寸 |
|
缩放图像至多个尺寸中的随机一个尺寸 |
|
随机灰度化 |
|
图像随机翻转 |
数据格式化¶
数据格式化操作通常是对数据进行的类型转换。
数据变换类 |
功能 |
|---|---|
将指定的数据转换为 |
|
将图像转换为 |
自定义数据变换类¶
要实现一个新的数据变换类,需要继承 BaseTransform,并实现 transform 方法。这里,我们使用一个简单的翻转变换(MyFlip)作为示例:
import random
import mmcv
from mmcv.transforms import BaseTransform, TRANSFORMS
@TRANSFORMS.register_module()
class MyFlip(BaseTransform):
def __init__(self, direction: str):
super().__init__()
self.direction = direction
def transform(self, results: dict) -> dict:
img = results['img']
results['img'] = mmcv.imflip(img, direction=self.direction)
return results
从而,我们可以实例化一个 MyFlip 对象,并将之作为一个可调用对象,来处理我们的数据字典。
import numpy as np
transform = MyFlip(direction='horizontal')
data_dict = {'img': np.random.rand(224, 224, 3)}
data_dict = transform(data_dict)
processed_img = data_dict['img']
又或者,在配置文件的 pipeline 中使用 MyFlip 变换
pipeline = [
...
dict(type='MyFlip', direction='horizontal'),
...
]
需要注意的是,如需在配置文件中使用,需要保证 MyFlip 类所在的文件在运行时能够被导入。