测试时增强(Test time augmentation)¶
测试时增强(Test time augmentation,后文简称 TTA)是一种测试阶段的数据增强策略,旨在测试过程中,对同一张图片做翻转、缩放等各种数据增强,将增强后每张图片预测的结果还原到原始尺寸并做融合,以获得更加准确的预测结果。为了让用户更加方便地使用 TTA,MMEngine 提供了 BaseTTAModel 类,用户只需按照任务需求,继承 BaseTTAModel 类,实现不同的 TTA 策略即可。
TTA 的核心实现通常分为两个部分:
测试时的数据增强:测试时数据增强主要在 MMCV 中实现,可以参考 TestTimeAug 的 API 文档,本文档不再赘述。
模型推理以及结果融合:
BaseTTAModel的主要功能就是实现这一部分,BaseTTAModel.test_step会解析测试时增强后的数据并进行推理。用户继承BaseTTAModel后只需实现相应的融合策略即可。
快速上手¶
一个简单的支持 TTA 的示例可以参考 examples/test_time_augmentation.py
准备 TTA 数据增强¶
BaseTTAModel 需要配合 MMCV 中实现的 TestTimeAug 使用,这边简单给出一个样例配置:
tta_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='TestTimeAug',
transforms=[
[dict(type='Resize', img_scale=(1333, 800), keep_ratio=True)],
[dict(type='RandomFlip', flip_ratio=0.),
dict(type='RandomFlip', flip_ratio=1.)],
[dict(type='PackXXXInputs', keys=['img'])],
])
]
该配置表示在测试时,每张图片缩放(Resize)后都会进行翻转增强,变成两张图片。
定义 TTA 模型融合策略¶
BaseTTAModel 需要对翻转前后的图片进行推理,并将结果融合。merge_preds 方法接受一列表,列表中每一个元素表示 batch 中的某个数据反复增强后的结果。例如 batch_size=3,我们对 batch 中的每张图片做翻转增强,merge_preds 接受的参数为:
# data_{i}_{j} 表示对第 i 张图片做第 j 种增强后的结果,
# 例如 batch_size=3,那么 i 的 取值范围为 0,1,2,
# 增强方式有 2 种(翻转),那么 j 的取值范围为 0,1
demo_results = [
[data_0_0, data_0_1],
[data_1_0, data_1_1],
[data_2_0, data_2_1],
]
merge_preds 需要将 demo_results 融合成整个 batch 的推理结果。以融合分类结果为例:
class AverageClsScoreTTA(BaseTTAModel):
def merge_preds(
self,
data_samples_list: List[List[ClsDataSample]],
) -> List[ClsDataSample]:
merged_data_samples = []
for data_samples in data_samples_list:
merged_data_sample: ClsDataSample = data_samples[0].new()
merged_score = sum(data_sample.pred_label.score
for data_sample in data_samples) / len(data_samples)
merged_data_sample.set_pred_score(merged_score)
merged_data_samples.append(merged_data_sample)
return merged_data_samples
相应的配置文件为:
tta_model = dict(type='AverageClsScoreTTA')
改写测试脚本¶
cfg.model = ConfigDict(**cfg.tta_model, module=cfg.model)
cfg.test_dataloader.dataset.pipeline = cfg.tta_pipeline
进阶使用¶
一般情况下,用户继承 BaseTTAModel 后,只需要实现 merge_preds 方法,即可完成结果融合。但是对于复杂情况,例如融合多阶段检测器的推理结果,则可能会需要重写 test_step 方法。这就要求我们去进一步了解 BaseTTAModel 的数据流以及它和各组件之间的关系。
BaseTTAModel 和各组件的关系¶
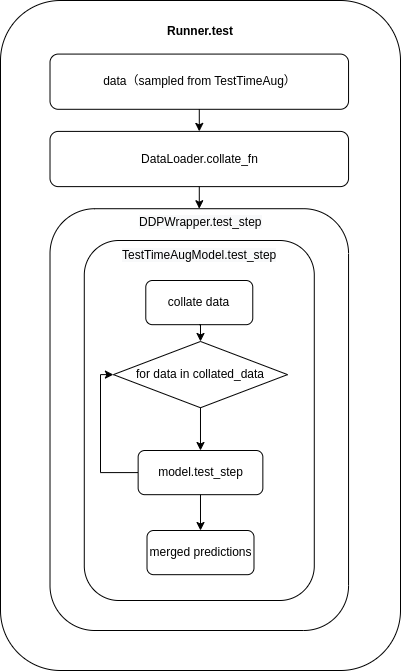
BaseTTAModel 是 DDPWrapper 和 Model 的中间层。在执行 Runner.test() 的过程中,会先执行 DDPWrapper.test_step(),然后执行 TTAModel.test_step(),最后再执行 model.test_step():
运行过程中具体的调用栈如下所示:
数据流¶
数据经 TestTimeAug 增强后,其数据格式为:
image1 = dict(
inputs=[data_1_1, data_1_2],
data_sample=[data_sample1_1, data_sample1_2]
)
image2 = dict(
inputs=[data_2_1, data_2_2],
data_sample=[data_sample2_1, data_sample2_2]
)
image3 = dict(
inputs=[data_3_1, data_3_2],
data_sample=[data_sample3_1, data_sample3_2]
)
其中 data_{i}_{j} 为增强后的数据,data_sample_{i}_{j} 为增强后数据的标签信息。
数据经过 DataLoader 处理后,格式转变为:
data_batch = dict(
inputs = [
(data_1_1, data_2_1, data_3_1),
(data_1_2, data_2_2, data_3_2),
]
data_samples=[
(data_samples1_1, data_samples2_1, data_samples3_1),
(data_samples1_2, data_samples2_2, data_samples3_2)
]
)
为了方便模型推理,BaseTTAModel 会在模型推理前将将数据转换为:
data_batch_aug1 = dict(
inputs = (data_1_1, data_2_1, data_3_1),
data_samples=(data_samples1_1, data_samples2_1, data_samples3_1)
)
data_batch_aug2 = dict(
inputs = (data_1_2, data_2_2, data_3_2),
data_samples=(data_samples1_2, data_samples2_2, data_samples3_2)
)
此时每个 data_batch_aug 均可以直接传入模型进行推理。模型推理后,BaseTTAModel 会将推理结果整理成:
preds = [
[data_samples1_1, data_samples_1_2],
[data_samples2_1, data_samples_2_2],
[data_samples3_1, data_samples_3_2],
]
方便用户进行结果融合。了解 TTA 的数据流后,我们就可以根据具体的需求,重载 BaseTTAModel.test_step(),以实现更加复杂的融合策略。